
Firebird 3 protocol benchmark
At the 12th Firebird Developers Day, I talked about Using Firebird in high latency networks (aka. internet). Below are two slides from my presentation, where you can see the improvements in Firebird 3 wire protocol, compared to FB 2.5 and to MySQL.
Enjoy!
Obs: Left axis values are expressed in seconds. Test server was hosted in Amazon (USA) and client accessing it was located in Brazil. Ping reported latency of 219ms. The smaller the bar, the better.
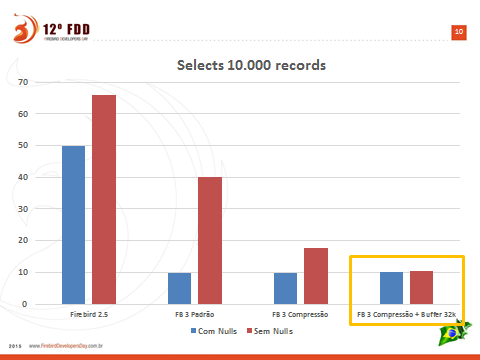
Above graph shows the result of fetching 10.000 records from a real table used to store customers data. Red bars represents records with all the fields filled (ie: there was no fields containing nulls) and blue bars represents fetching records where some of the fields were nulls. Tests where done with and without compression.
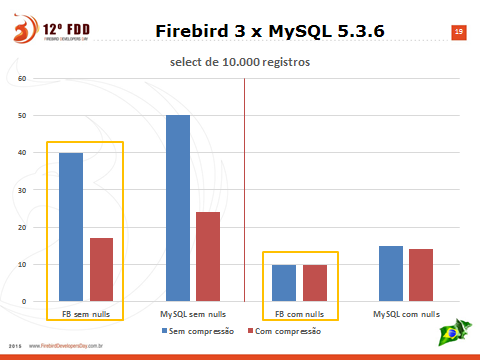
The same table used in previous graph was created in MySQL InnoDB (same data). Blue bars means that wire compression was disabled, and red has compression enabled. Left side graphs has all fields filled (ie. there wasn’t null fields) and in right side graphs, some records has some null fields.
As you see, FB 3 won 😉
I should mention that there was no blob fields in the table, and this makes a lot of difference. Fetching non-null blobs makes the fetch slower in Firebird (more roundtrips are needed).
PS: The improvements in the FB 3 wire protocol were sponsored by donations collected in the 9th edition of FDD conference, and were implemented by Dmitry Yemanov. Compression was implemented by Alex Peshkov.